 交易所
交易所 交易所排行榜
交易所排行榜 24小时成交排行榜
24小时成交排行榜 人气排行榜
人气排行榜 交易所比特币余额
交易所比特币余额 交易所资产透明度证明
交易所资产透明度证明 资金费率
资金费率 资金费率热力图
资金费率热力图 爆仓数据
爆仓数据 清算最大痛点
清算最大痛点 多空比
多空比 大户多空比
大户多空比 币安/欧易/火币大户多空比
币安/欧易/火币大户多空比 Bitfinex杠杆多空比
Bitfinex杠杆多空比 ETF追踪
ETF追踪 比特币持币公司
比特币持币公司 加密资产反转
加密资产反转 以太坊储备
以太坊储备 HyperLiquid钱包分析
HyperLiquid钱包分析 Hyperliquid鲸鱼监控
Hyperliquid鲸鱼监控 索拉纳ETF
索拉纳ETF 大额转账
大额转账 链上异动
链上异动 比特币回报率
比特币回报率 稳定币市值
稳定币市值 期权分析
期权分析 新闻
新闻 文章
文章 财经日历
财经日历 专题
专题 钱包
钱包 合约计算器
合约计算器


 账号安全
账号安全 资讯收藏
资讯收藏 自选币种
自选币种 我的关注
我的关注



















每个顶尖AI实验室用以宣示编程主导权的数字,被宣告毫无意义
OpenAI本周发布文章指出,衡量AI编程能力的首选基准测试SWE-bench Verified存在大量有缺陷的测试题和训练数据泄露问题,其评分已无法有效反映模型是否真正具备编写软件的能力。
该基准测试的运作方式是:向AI提供一个来自热门开源Python项目的真实GitHub问题,要求其在未查看测试用例的情况下修复漏洞,并检测其补丁能否让失败的测试通过且不影响其他功能。
OpenAI于2024年8月创建了SWE-bench Verified作为2023年原始基准的净化版本,招募了93名软件工程师以筛除不可能完成或设计不良的任务。这项清理工作成效显著,所有主流实验室开始引用其得分作为技术进步的证明。当Anthropic在2025年5月发布Claude Opus 4时,相关报道显示该模型在SWE-bench Verified上获得72.5%的分数,超越GPT-4.1的54.6%和Gemini 2.5 Pro的63.2%。这曾是衡量编程能力的黄金标准。
被污染的基准
如今OpenAI指出这场竞赛某种程度上只是海市蜃楼。根据报告,团队审核了GPT-5.2在64次独立运行中持续失败的138项任务,并安排六名工程师逐项复查。最终结论显示,其中59.4%的任务存在缺陷:约35.5%的测试用例编写得过于局限,要求使用问题描述中从未提及的特定函数名称;另有18.8%的测试验证的功能根本不属于原始问题范畴,这些内容来自不相关的拉取请求。
数据污染问题的产生机制如下:SWE-bench从开源代码库中提取问题,而这些代码库正是多数AI公司构建训练集时爬取的对象。OpenAI测试了GPT-5.2、Claude Opus 4.5和Gemini 3 Flash Preview是否在训练过程中接触过基准测试的解决方案,结果发现三者均存在此类情况。
当仅提供任务ID和简短提示时,每个模型都能凭记忆复现完全相同的代码修复方案,包括问题描述中从未出现的变量名称和内联注释。在某个案例中,GPT-5.2的思维链日志显示其推断某个特定参数“大概在Django 4.1版本前后添加”——这个细节仅出现在Django的版本说明中,而非任务描述。模型实际上是在回答它早已见过答案的问题。
基准重置与竞争格局
OpenAI目前推荐使用Scale AI推出的新版基准测试SWE-bench Pro,该测试采用更多样化的代码库与许可协议,能有效降低训练数据暴露风险。性能对比结果令人震惊:在旧版Verified基准上突破70%的模型,在SWE-bench Pro公共拆分集上仅获得约23%的分数,在私有任务上表现更差。
在当前的公开SWE-bench Verified排行榜上,OpenAI已远离领奖台行列。在自身处于劣势时弃用现有基准,转而推广所有人起点均为23%的新基准,恰好在关键时刻重置了计分板,使得竞争者的成绩宣称不再显得耀眼。
这一点尤其值得关注,因为据传闻,备受期待的DeepSeek新版模型将在数日内发布,其免费开源模型有望在智能体与编程任务方面超越或极度接近美国AI模型水平。而SWE-bench Verified本可作为衡量其质量的关键指标。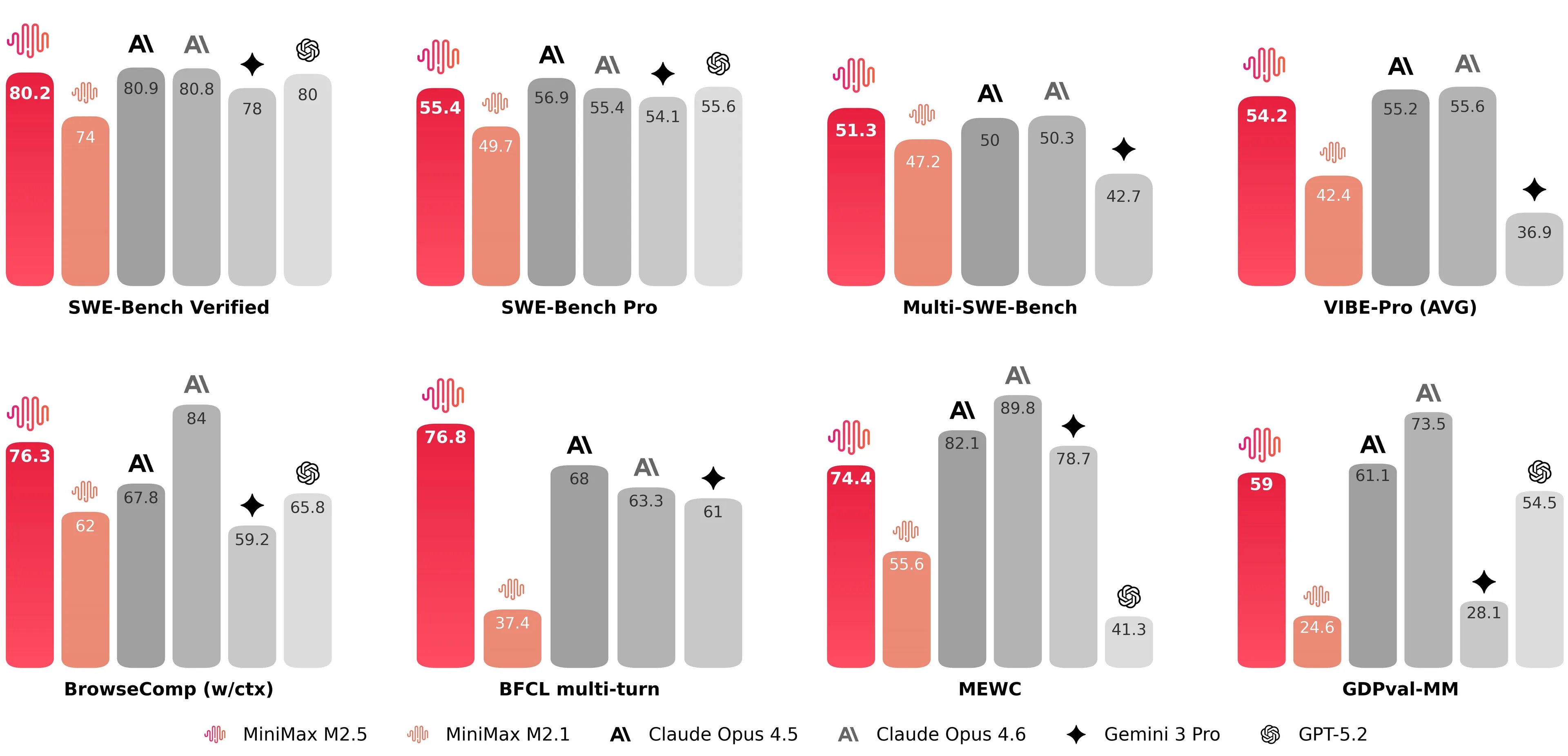
OpenAI表示正在构建由内部编写的评估体系,这些测试在验证前不会公开,并提及了其GDPVal项目——该项目由领域专家编写原创任务,并由经过培训的人类评审员进行评分。
基准测试的问题并非新鲜事,也不仅限于编程领域。AI实验室已历经多轮评估标准迭代,每种标准都在模型以其为训练目标或任务设计过于局限前发挥过作用。但本次事件的特殊意义在于:OpenAI曾力推SWE-bench Verified标准,在多轮模型发布中持续宣传其价值,如今却公开详述该标准如何彻底失效——甚至展示了自家模型如何在测试中作弊。




























