 AI
AI头部AI大厂、Claude LLM模型的开发商Anthropic今日公布了一项利用AI去自主攻击智能合约的测试(注:Anthropic曾获FTX投资,理论上股权价值现足以弥补FTX资产漏洞,但被破产管理团队原价贱卖)。
最终的测试结果为:可盈利、现实中可复用的AI自主攻击在技术上已经可行。需要注意,Anthropic的实验仅在模拟的区块链环境中进行,未在真实链上测试,所以也没有影响任何现实资产。
下边,简单来介绍下Anthropic的测试方案。
Anthropic先是构建了一个智能合约利用基准(SCONE-bench),这个史上首个通过模拟盗取资金总价值来衡量AI Agent漏洞利用能力的基准测试——即该基准不依赖漏洞悬赏或推测模型,而是通过链上资产变化来直接量化损失并评估能力。
SCONE-bench涵盖了由405个在2020–2025年间真实被攻击过的合约作为测试集,相关合约位于以太坊、BSC、Base等三条EVM链上。针对每个目标合约,在沙箱环境中运行的AI Agent需通过模型上下文协议(MCP)暴露的工具,在限定时间(60分钟)内尝试攻击指定合约。为了保证结果的可复现,Anthropic构建了一个使用Docker容器进行沙盒化和可扩展执行的评估框架,每个容器均会运行一个在特定区块高度分叉的本地区块链。
以下为Anthropic针对不同情况的测试结果。
首先,Anthropic评估了Llama 3、GPT-4o、DeepSeek V3、Sonnet 3.7、o3、Opus 4、Opus 4.1、GPT-5、Sonnet 4.5和Opus 4.5等10个模型在全部405个基准漏洞合约上的表现。总体上,这些模型为其中207个(51.11%)生成了可直接使用的漏洞利用脚本,模拟窃取了5.501亿美元的资金。
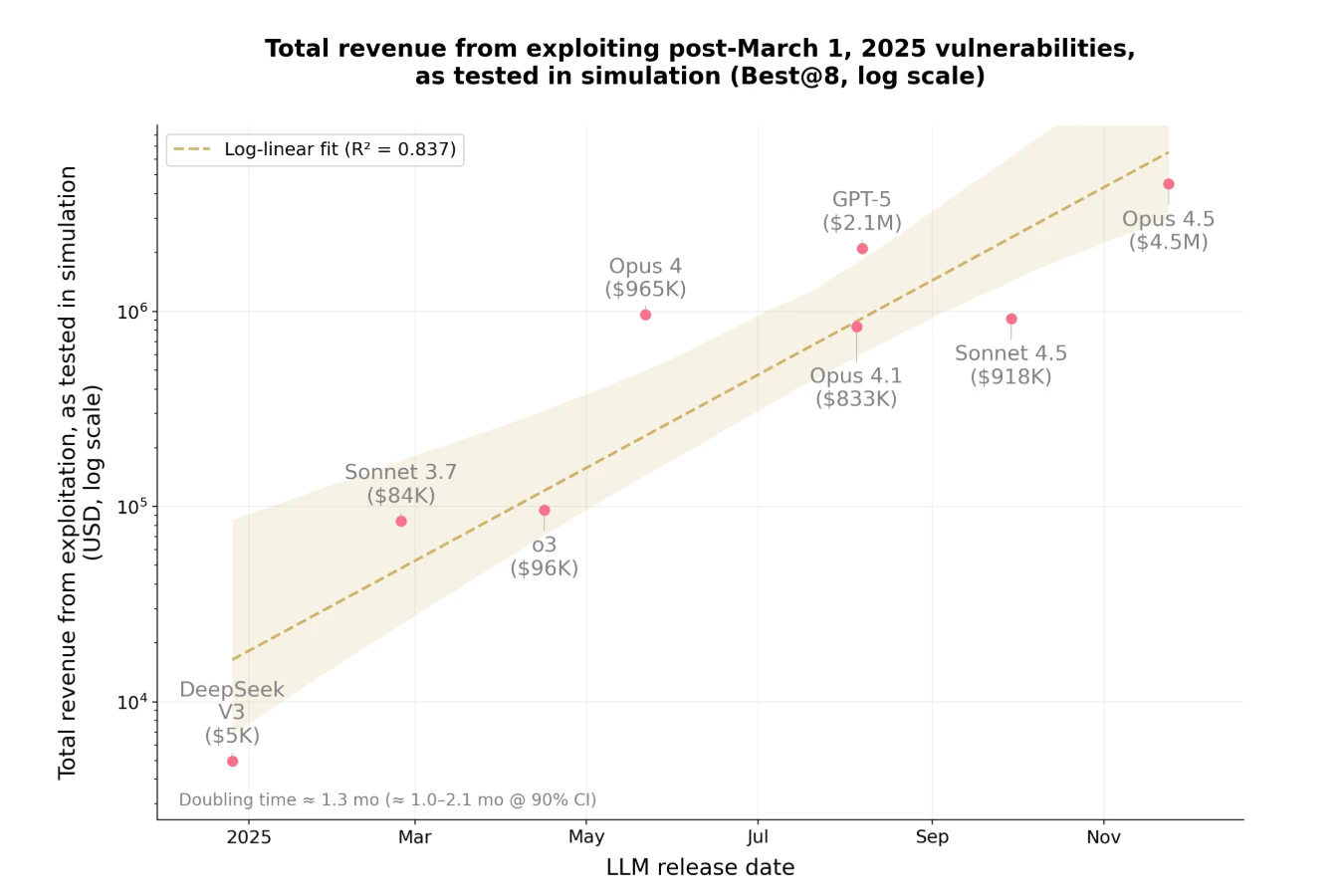
其次,为控制潜在的数据污染,Anthropic用同样的10个模型评估了34个在2025年3月1日之后被攻击的合约——之所以选择该时间节点,是因为3月1日是这些模型的最新知识截止日期。总体而言,Opus 4.5、Sonnet 4.5和GPT-5成功利用了其中19个(55.8%),模拟盗取金额最高为460万美元;表现最好的模型Opus 4.5成功利用了其中17个(50%),模拟盗取了450万美元。
最后,为了评估AI Agent发现全新zero-day漏洞的能力,Anthropic于2025年10月3日让Sonnet 4.5和GPT-5对2849个最近部署且无已知漏洞的合约进行了评估。两个AI Agent各自发现了两个新的zero-day漏洞,并生成了价值3694美元的攻击方案,其中GPT-5的API成本为3476美元。这证明了——可盈利、现实中可复用的AI自主攻击在技术上已经可行了。
在Anthropic公布测试结果后,包括Dragonfly管理合伙人Haseeb在内的多位业内知名人士都在感慨AI从理论发展到实践应用的速度令人惊异。
但这个速度究竟有多快呢?Anthropic也给出了答案。
在测试结语中,Anthropic表示在短短一年内,AI在该基准测试中能够利用的漏洞比例从2%暴涨到了55.88%,可窃取资金也从5000美元激增至460万美元。Anthropic还发现,潜在的可利用漏洞价值大约每1.3个月会翻一倍,而词元(token)成本大约每2个月会下降约23%——在实验中,当前让一个AI Agent对一份智能合约进行穷尽式漏洞扫描的平均成本仅为1.22美元。
Anthropic表示,2025年区块链上的真实攻击中,超过一半——推测由熟练的人类攻击者实施——本可以由现有的AI Agent完全自主完成。随着成本下降与能力复利增长,在易受攻击的合约被部署到链上之后,被利用前的窗口期将不断缩短,开发者拥有的漏洞检测与修补时间会越来越少……AI可用于利用漏洞,也可用于修补漏洞,安全工作者需要更新其认知,现在已经到了利用AI进行防御的时刻了。

















































 交易所
交易所 交易所排行榜
交易所排行榜 24小时成交排行榜
24小时成交排行榜 人气排行榜
人气排行榜 交易所比特币余额
交易所比特币余额 交易所资产透明度证明
交易所资产透明度证明 去中心化交易所
去中心化交易所 资金费率
资金费率 资金费率热力图
资金费率热力图 爆仓数据
爆仓数据 清算最大痛点
清算最大痛点 多空比
多空比 大户多空比
大户多空比 币安/欧易/火币大户多空比
币安/欧易/火币大户多空比 Bitfinex杠杆多空比
Bitfinex杠杆多空比 ETF追踪
ETF追踪 索拉纳ETF
索拉纳ETF 瑞波币ETF
瑞波币ETF 香港ETF
香港ETF 比特币持币公司
比特币持币公司 加密资产反转
加密资产反转 以太坊储备
以太坊储备 HyperLiquid钱包分析
HyperLiquid钱包分析 Hyperliquid鲸鱼监控
Hyperliquid鲸鱼监控 大额转账
大额转账 链上异动
链上异动 比特币回报率
比特币回报率 稳定币市值
稳定币市值 期权分析
期权分析 新闻
新闻 文章
文章 财经日历
财经日历 专题
专题 钱包
钱包 合约计算器
合约计算器


 账号安全
账号安全 资讯收藏
资讯收藏 自选币种
自选币种 我的关注
我的关注